
목차
- 2장. 객체 생성과 파괴
- 아이템 1 - 생성자 대신 정적 팩터리 메서드를 고려하라
- 정적 팩터리 메서드에 흔히 사용하는 명명 방식들
- 아이템 2 - 생성자에 매개변수가 많다면 빌더를 고려하라.
- 아이템 3 - private 생성자나 열거 타입으로 싱글턴임을 보증하라
- 아이템 4 - 인스턴스화를 막으려거든 private 생성자를 사용하라
- 아이템 5 - 자원을 직접 명시하지 말고 의존 객체 주입을 사용하라
- 아이템 6 - 불필요한 객체 생성을 피하라
- 아이템 7 - 다 쓴 객체 참조를 해제하라
- 아이템 8. finalizer와 cleaner 사용을 피하라
- 아이템 9. try-finally보다는 try-with-resources를 사용하라
* 책 내용 자체 정리 보다는 제가 각 아이템을 이해한 방식대로 제 생각을 주저리주저리 적는 글 입니다. 따라서 틀린 내용이 있을 수 있습니다.
2장. 객체 생성과 파괴
아이템 1 - 생성자 대신 정적 팩터리 메서드를 고려하라
장점 1 - 이름을 가질 수 있다.
생성자에는 이름을 줄 수 없으므로 실수의 여지가 많다. 또한 생성자에 어떠한 의미를 부여하기도 힘들다. 따라서 정적 팩터리 메소드에 이름을 주면 사용하는 쪽에서도 실수의 여지를 많이 줄일 수 있다. 이하 코드에서 생성자를 통한 생성은 타입 혹은 boolean 처럼 판단 기준을 넘겨줘야 한다. 정적 팩터리 메서드를 사용한게 더 깔끔하고 실수의 여지도 적을 것 같다.
new Member("nahwasa", MemberType.ADMIN);
new Member("user1", MemberType.USER);
Member.createAdmin("nahwasa");
Member.createUser("user1");
장점 2 - 호출될 때마다 인스턴스를 새로 생성하지는 않아도 된다.
new를 통해 생성자를 호출할 경우 인스턴스는 당연히 새로 생성된다. 정적 팩토리 메서드는 단순히 static이 붙은 함수의 형태이므로 개발자가 인스턴스의 생성에 대해 제어 가능하다. 싱글톤 패턴을 생각해보면 쉽게 이해할 수 있다.
class ConnectionManager {
private ConnectionManager() {}
private static class ConnectionManagerHolder {
private static final ConnectionManager instance = new ConnectionManager();
}
public static ConnectionManager getInstance() {
return ConnectionManagerHolder.instance;
}
}
장점 3 - 반환 타입의 하위 타입 객체를 반환할 수 있는 능력이 있다.
객체지향과도 밀접한 내용인 것 같다. 정적 팩토리 메서드와는 다른 방식이긴 하지만 스프링과 비슷하게 생각해보면 될 것 같다. MemberRepository를 사용하는 쪽에서는 구현체들을 사용하지 않고, MemberRepository에 의존성을 가지고 사용하게 된다. 이로써 [A]를 [B]로 변경하더라도 사용하는쪽에서는 코드 변경 없이 사용 가능하다.
@Bean
public MemberRepository memberRepository() {
[A] return new JdbcTemplateMemberRepository(dataSource);
[B] return new JpaMemberRepository(em);
}
...
@Controller
public class MemberController {
private final MemberService memberService;
public MemberController(MemberService memberService) {
this.memberService = memberService;
}
...
}
정적 팩토리 메서드도 마찬가지로 추상 타입으로 리턴함으로써 변경에 더 유연한 코드를 짤 수 있다. (예시는 장점 4에)
장점 4. 입력 매개변수에 따라 매번 다른 클래스의 객체를 반환할 수 있다.
장점 3, 4를 합친 예시는 아래와 같다. type에 따라 매번 다른 클래스의 객체를 반환할 수 있고, LgRemoteControl과 SamsungRemoteControl의 부모인 RemoteControl 타입으로 리턴하므로 반환 타입의 하위 타입 객체를 반환하게 된다.
interface RemoteControl {
void channelUp();
void channelDown();
static RemoteControl of(String type) {
switch (type) {
case "lg" : return new LgRemoteControl();
case "samsung" : return new SamsungRemoteControl();
}
return null;
}
}
class LgRemoteControl implements RemoteControl {
@Override
public void channelUp() {/*LG에 맞게 구현*/}
@Override
public void channelDown() {/*LG에 맞게 구현*/}
}
class SamsungRemoteControl implements RemoteControl {
@Override
public void channelUp() {/*삼성에 맞게 구현*/}
@Override
public void channelDown() {/*삼성에 맞게 구현*/}
}
장점 5. 정적 팩터리 메서드를 작성하는 시점에는 반환할 객체의 클래스가 존재하지 않아도 된다.
스터디에서 이 부분에서 스터디원들이 좀 어려워했었다. 내가 잘못 이해한걸수도 있겠지만, 난 그냥 말 그대로 이해했다. 책에 나온 JDBC 예제의 경우, JDBC 라이브러리를 만든 사람의 입장에서 다양한 DB와 해당 DB들의 버전업까지 전부 파악해가며 드라이버를 만들어줄 순 없다. 따라서 제공자 등록 API를 제공해 각 DB 제작자가 JDBC를 지원되게 하려면 드라이버를 만들게 하면 된다. 이 때, JDBC 라이브러리를 만든 사람 입장에서 JDBC를 작성할 때 드라이버가 존재하는지는 중요하지 않고 없어도 상관없다. 없으면 에러내면 그만이다. 그냥 알맞은 드라이버를 DB 제작자가 드라이버로 제공했고, JDBC의 서비스 접근 API를 사용하는 사용자가 해당 드라이버를 등록해뒀다면 사용할 수 있는 것이다.
생각이 맞는지 확인해보려고 'JDBC 연결'로 검색하니 나온 글들에 공통적으로 'DriverManager.getConnection()' 으로 커넥션을 가져옴을 알 수 있었다. 그래서 DriverManager를 들어가서 getConnection을 확인해봤다. registeredDrivers 에서 isDriverAllowd가 통과된게 있다면 그걸 리턴해주고, 없다면 실패하는 모습을 볼 수 있다. 즉, JDBC 입장에서는 '작성하는 시점에(=컴파일 타임에)' 반환할 객체의 클래스가 존재하지 않아도상관없다. 이제 제공자 등록 API에서는 저 registeredDrivers에 드라이버를 등록하는 API가 제공될 것 같다.

비단 정적 팩토리만 생각할게 아니고, 책에서 서비스 제공자 프레임워크 패턴의 여러 변형 중 하나인 의존 객체 주입 프레임워크를 생각해보자. 스프링부트에서도 마찬가지인데, 빈을 스프링 컨테이너에 등록 시 '작성하는 시점에' 실제 구현체의 존재여부는 관계가 없다. 런타임까지 가도 구현체가 없다면 에러가 날 뿐이지, 컴파일 타임에 에러가 나진 않는다.
@Bean
public PasswordEncoder passwordEncoder() {
// return new BCryptPasswordEncoder();
return null;
}
...
@Service
public class RegisterMemberService {
private final PasswordEncoder passwordEncoder;
private final MemberRepository repository;
@Autowired
public RegisterMemberService(PasswordEncoder passwordEncoder, MemberRepository repository) {
this.passwordEncoder = passwordEncoder;
this.repository = repository;
}
public Long join(String userid, String pw) {
Member member = Member.createUser(userid, pw, passwordEncoder);
validateDuplicateMember(member);
repository.save(member);
return member.getId();
}
}
단점 1. 상속을 하려면 public이나 protected 생성자가 필요하니 정적 팩터리 메서드만 제공하면 하위 클래스를 만들 수 없다.
A클래스의 생성자를 private으로 막아두면 extends A 와 같은 형태로 사용할 수 없다. 그 얘기이다.
단점 2. 정적 팩터리 메서드는 프로그래머가 찾기 어렵다.
아무래도 모든 자바 프로그램에 통용되는 생성자 사용 규칙에 비해, 개발자가 직접 만들어둔 함수이므로 생성자보다 찾기 어려운게 당연하다.
정적 팩터리 메서드에 흔히 사용하는 명명 방식들
from
매개변수를 하나 받아서 해당 타입의 인스턴스를 반환하는 형변환 메서드
Date d = Date.from(instant);(책에선 Date로 예시가 나왔는데, TMI로 Date와 Calendar는 안쓰는게 좋다. 참고 링크)
of
여러 매개변수를 받아 적합한 타입의 인스턴스를 반환하는 집계 메서드
LocalDate.of(2023, 2, 5)
valueOf
from과 of의 더 자세한 버전
String.valueOf(10);
instance, getInstance
(매개변수를 받는다면) 매개변수로 명시한 인스턴스를 반환하지만, 같은 인스턴스임을 보장하지는 않는다. (싱글턴 구현에서 주로 getInstance() 를 많이 사용한다.)
StackWalker luke = StackWalker.getInstance(options);
create, newInstance
instance 혹은 getInstance와 같지만, 매번 새로운 인스턴스를 생성해 반환함을 보장한다.
Array.newInstance(classObject, arrayLen);
getType
getInstance와 같으나, 생성할 클래스가 아닌 다른 클래스에 팩터리 메서드를 정의할 때 쓴다. "Type"은 팩터리 메서드가 반환할 객체의 타입이다.
BufferedReader br = Files.newBufferedReader(path);
type
getType과 newType의 간결한 버전
List<Complaint> litany = Collections.list(legacyLitany);
아이템 2 - 생성자에 매개변수가 많다면 빌더를 고려하라.
특히 필수값이 일부분인 경우 빌더를 사용하는게 좋은 경우가 많다. 빌더의 단점은 코드가 길어진다. 이건 사실 lombok 쓰면 해결된다. 다만 롬복 사용 시 일부 필수값 지정이 불가하다(억지로 가능하게 할 순 있으나, 구조가 너무 별로가 된다. 억지로 할꺼면 그냥 롬복 @Builder 빼버리고 그 부분은 빌더패턴을 직접 짜는게 나아보인다.).
당연히 모든 값이 필수값이면 빌더를 쓸 이유가 없고, 오히려 필수값 체크만 귀찮아진다. 개인적으로는 다음과 같이 쓰는걸 선호한다.
A. 모두 필수값 : 생성자
B. 필수값이 없음 : 빌더 (롬복 사용)
C. 일부라도 필수값이 있음 : 생성자
C의 경우 너무 파라미터가 많다면 당연히 조합의 수가 늘어나서 이상해진다. 이 경우 객체로 뺄 수 있는 부분은 묶어서 객체로 빼면 될 것 같다. 그래도 많다면 책임이 너무 한쪽 클래스에 쏠리지 않았는지 좀 생각해봐야할 것 같다.
객체로 빼는건 예를들어서 아래와 같은 경우이다.
new Circle(int x, int y, int radius)
->
new Circle(Point point, int radius)
책 19쪽에 나온 계층적으로 설계된 빌더 패턴은 코드를 이해하기 어려울 수 있다. 대강 얘기해보자면..
1. EnumSet
Enum용 set이다. HashSet 같은거라고 보면되는데, Enum에 대해 사용할 수 있는 자료구조라고 보면 된다. Enum에 대해 더 빠르게 동작 가능하다.
2. protected abstract T self();
abstract로 만들어둔걸 abstract 클래스에서 사용하는 방식은 '템플릿 메소드 패턴' 찾아보면 이해할 수 있을 것 같다.
3. Builder<T extends Builder<T>>
아마 이게 가장 이해안될 것 같다. 제너릭으로 제약을 건 거라고 보면 된다. 순서대로 아래처럼 봐보면 이해될수도 있다.
A. Builder 만 있었다면(제너릭 없었다면) : 여러 종류의 피자를 지원할 수 없다. 즉, 계층적으로 못쓴다.
B. Builder<T> 까지였다면 : 피자 Builder인데 Builder<String> 처럼 피자가 아닌애도 올 수 있다.
C. Bulder<T extends Builder> 까지였다면 : NyPizza에 Calzone 빌더가 올 수 있다.
D. Builder<T extends Builder<T>> : NyPizza 빌더라면 NyPizza 자신만 가능하다!
즉, 'B' 까지만 사용했어도 이 코드는 정상적으로 동작하는데, 제약을 걸기위해 C를 거쳐 D가 사용된 것이다.
아이템 3 - private 생성자나 열거 타입으로 싱글턴임을 보증하라
이 책에서는 열거 타입 방식의 싱글턴이 가장 좋은 방법이라고 나와있다. 하지만 열거 타입을 싱글턴으로 사용하는건 용법에서 벗어난 사용이라고 생각되기도 한다. 코드에 열거 타입이 있는데 클래스 다이어그램만 보고 싱글턴인지 알 수 있을까? 절대 아닐거다.
근데 싱글턴의 제약조건을 가장 잘 만족시키는건 열거 타입이 맞긴하다. 그러니 취향껏 쓰면 될 것 같다. 내 경우엔 어차피 스프링부트를 주로 쓰기때문에 싱글턴을 직접 짤 일이 잘 없을 것 같다.
싱글턴의 여러 형태는 '자바 싱글톤 패턴의 변화 (다양한 싱글톤 패턴 구현 방법)' 글에 적어두었다. 취향껏 5번이나 6번을 쓰면 될 것 같다.
아이템 4 - 인스턴스화를 막으려거든 private 생성자를 사용하라
생성자를 private A() {} 처럼 private으로 두면 new A(); 와 같이 생성이 불가능하다. 싱글턴 구현을 봐보자. 정적 팩토리 메소드인 getInstance()으로 객체를 얻는걸 강제하기 위해 생성자를 private으로 두어 new로 생성되는걸 막아둔 형태이다.
class ConnectionManager {
private ConnectionManager() {}
private static class ConnectionManagerHolder {
private static final ConnectionManager instance = new ConnectionManager();
}
public static ConnectionManager getInstance() {
return ConnectionManagerHolder.instance;
}
}
아이템 5 - 자원을 직접 명시하지 말고 의존 객체 주입을 사용하라
예를 들어 unitPrice * usage를 통한 최종 금액에서, 할인율 20%(소수점 내림)를 적용하려고 한다. 아래처럼 짤 수 있을 것이다.
@Override
public long calculateEachCharge(CityGasUser user) {
long unitPrice = user.getUnitPrice();
long usage = user.getUsage();
return unitPrice * usage * 80 / 100;
}
이런 매직 넘버는 차후 찾기도 힘들고, 클라이언트 입장에서 할인율을 변경할수도 없고, 저 소스를 가지고 운영하는 사람 입장에서 할인율을 알려면 소스를 전부 까봐서 찾는 수밖에 없다. 아래는 생성자에서 주입받아 사용하는 코드이다.
public class VulnerableCityGasChargeService extends CityGasChargeService {
private final int discountRate;
public VulnerableCityGasChargeService(CityGasUserService cityGasUserService, int discountRate) {
super(cityGasUserService);
this.discountRate = discountRate;
}
@Override
public long calculateEachCharge(CityGasUser user) {
long unitPrice = user.getUnitPrice();
long usage = user.getUsage();
return unitPrice * usage * (100-discountRate) / 100;
}
}
이와 관련된 이야기 및 TDD, SOLID 등을 합쳐서 적어본 내용을 'TDD, Mock, SOLID 얘기 - 도시 가스 요금 계산' 에서 볼 수 있다.
아이템 6 - 불필요한 객체 생성을 피하라
책에 String, 정규식, 오토박싱 관련한 예시가 나와있다. String의 경우 literal로 코드에 작성 시 힙 영역의 String Constant Pool이 객체가 저장된다. 이후 동일한 literal에 대해 이미 생성되어 있는 객체가 반환된다(플라이웨이트 패턴 처럼).
// [A]
String str1 = "abc";
String str2 = "abc";
System.out.println(str1 == str2); // true
System.out.println(str1.equals(str2)); // true
// [B]
String str1 = "abc";
String str2 = new String("abc");
System.out.println(str1 == str2); // false;
System.out.println(str1.equals(str2)); // true
// [C]
String str1 = "abc";
String str2 = new String("abc").intern();
System.out.println(str1 == str2); // true
System.out.println(str1.equals(str2)); // true[A]는 설명한대로 String Constant Pool에 들어있는 두개를 비교하게 된다. 따라서 == 으로도 동일한 객체이므로 (주소값이 동일하므로) 동일하다고 뜬다. equals로는 당연히 true이다.
[B]는 new로 생성한 경우이다. 이 경우 String Constant Pool에서 가져오지 않으므로 서로 다른 객체가 되어(주소값이 달라서) == 으로는 비교할 수 없다.
[C]는 intern() 함수를 사용해 직접 String Constant Pool에 넣은 경우이다. 이 경우 [A] 와 동일하게 동작한다.
결론은 전부 intern()을 사용하거나, 완벽히 통제한게 아닌 이상 그냥 equals() 를 써서 비교하면 된다. 예전에 어떤 레거시 코드 공통코드에 String 비교를 ==으로 하길래 프로젝트 전체를 버린적이 있다. 공통이 그런식이면 나머진 안봐도 뻔하다.
또한 비단 String 뿐 아니라, primitive 타입의 wrapper 클래스를 사용 시에도 특히 조심해야 하는 얘기이다.
Integer a = 5;
Integer b = 5;
System.out.println(a == b);
System.out.println(a.equals(b));
Integer c = 500;
Integer d = 500;
System.out.println(c == d);
System.out.println(c.equals(d)); 위의 경우는 어떨까? 이건 예상하기 많이 힘들 것 같다. 결론은 a==b는 true지만, c==d는 false이다. Integer의 경우 [-128, 127] 범위 이내에 대해 캐싱한다. 따라서 a와 b는 캐싱되서 동일한 객체이고, c와 d는 500이라 캐싱된 범위를 넘어간 값이라 false이다. 그러니 아무튼 primitive 타입이 아니라면 equals로 비교하자. 물론 힙에 들어간 애들의 경우 ==으로 비교하는게 당연히 더 속도가 빠르다. 근데 속도 생각할꺼면 애초에 자바를 안써야.. 읍읍
(TMI - jvm 옵션으로 AutoBoxCacheMax을 줘서 캐싱되는 범위를 조절할 수 있다. default가 [-128, 127] 이다. jvm 옵션 검색 사이트)
오토박싱 관련 내용도 중요할 것 같다. 이 책에선 시간 차이만 얘기했지만, 사실 int는 4바이트이고 Integer는 20바이트정도이다. 즉, 메모리 차이도 있으므로 아무생각 없이 오토박싱되게 하면 여러모로 비효율적이다.
아이템 7 - 다 쓴 객체 참조를 해제하라
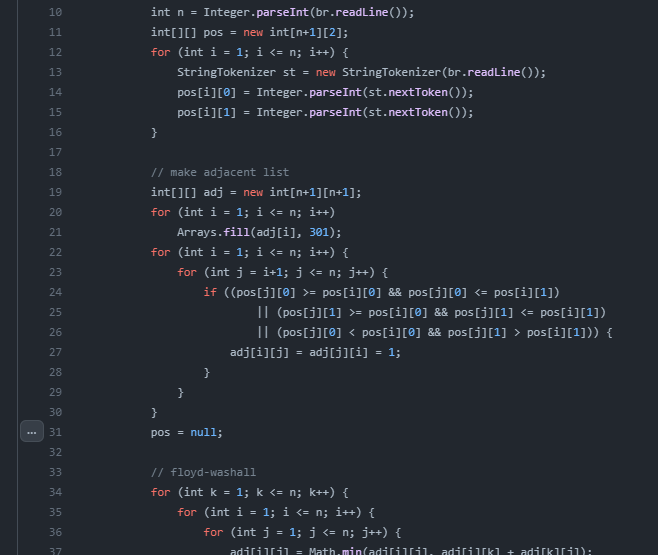
이 부분은 뭐 맞는말이긴 하지만, 크게 공감은 안됬다. GC 처리 안되도록 망치는게 더 힘들지 않나? 생각된다. 알고리즘 문제 풀 때 메모리 초과 날 때 직접 객체 참조를 해제하는 경우는 꽤 많이 있지만, 실무에서 코드 구조 잘 나누었고, 정말 엉뚱한 코드를 짜지 않는이상 문제가 생길일이 있을지 잘 모르겠다. 이하 백준 14588번을 푼 코드이다. 알고리즘 풀이의 경우 아무래도 절차지향적으로 짜기 좋은 경우가 많다보니 해당 객체로 처리할 부분은 다 해서 필요가 없더라도 한 함수에 메모리가 해제되지 않는 변수가 존재할 수 있어 메모리가 부족하다면 아래처럼 해제해주는 편이다(pos = null;).
아이템 8. finalizer와 cleaner 사용을 피하라
아이템 9. try-finally보다는 try-with-resources를 사용하라
결론은 finalizer, cleaner를 사용하지 말고 AutoCloseable을 구현해서 사용하자! 그리고 AutoCloseable 구현해둔걸 사용하는 부분에선 try-with-resources로 사용해주면 된다. 대부분의 자바 라이브러리 함수들은 AutoCloseable이 구현되어 있으므로, try-catch 보다는 try-with-resources를 사용하자.
'Development > Java' 카테고리의 다른 글
| [객사오 정리] 1장. 협력하는 객체들의 공동체 (0) | 2023.04.26 |
|---|---|
| 기본적인 자바 람다(Lambda) (0) | 2023.04.03 |
| 자바에서 N개짜리 배열 생성은 O(N)이 걸린다. (C++, C 도 마찬가지) (2) | 2023.03.13 |
| 자바에서 문자열 합칠 때 '+' 연산을 쓰지 마세요! (StringBuilder, StringJoiner, String.join, StringBuffer) (0) | 2023.03.07 |
| 자바 날짜 관련 코딩 시 Date와 Calendar를 쓰지 마세요! (0) | 2023.02.06 |




댓글